A Set of executable programmes or collection of programmes in a computer is called Software.
Tuesday, 6 November 2018
Friday, 24 August 2018
Difference between Data warehouse and Business Intelligence
Difference between Data warehouse and Business Intelligence
Data warehouse is a way of storing data and creating information through leveraging data marts. Data marts are segments or categories of information and/or data that are grouped together to provide 'information' into that segment or category. Data warehouse does not require Business Intelligence to work. Reporting tools can generate reports from the DW.
Business Intelligence is the leveraging of DW to help make business decisions and recommendations. Information and data rules engines are leveraged here to help make these decisions along with statistical analysis tools and data mining tools.
The Business Intelligence tool that we are going to learn is SSIS which uses SQL as the Backend, Sonow let us learn the SQL BasicsDifference between Data warehouse and Business Intelligence
Data warehouse is a way of storing data and creating information through leveraging data marts. Data marts are segments or categories of information and/or data that are grouped together to provide 'information' into that segment or category. Data warehouse does not require Business Intelligence to work. Reporting tools can generate reports from the DW.
Business Intelligence is the leveraging of DW to help make business decisions and recommendations. Information and data rules engines are leveraged here to help make these decisions along with statistical analysis tools and data mining tools.
The Business Intelligence tool that we are going to learn is SSIS which uses SQL as the Backend, Sonow let us learn the SQL Basics
Data warehouse is a way of storing data and creating information through leveraging data marts. Data marts are segments or categories of information and/or data that are grouped together to provide 'information' into that segment or category. Data warehouse does not require Business Intelligence to work. Reporting tools can generate reports from the DW.
Business Intelligence is the leveraging of DW to help make business decisions and recommendations. Information and data rules engines are leveraged here to help make these decisions along with statistical analysis tools and data mining tools.
The Business Intelligence tool that we are going to learn is SSIS which uses SQL as the Backend, Sonow let us learn the SQL BasicsDifference between Data warehouse and Business Intelligence
Data warehouse is a way of storing data and creating information through leveraging data marts. Data marts are segments or categories of information and/or data that are grouped together to provide 'information' into that segment or category. Data warehouse does not require Business Intelligence to work. Reporting tools can generate reports from the DW.
Business Intelligence is the leveraging of DW to help make business decisions and recommendations. Information and data rules engines are leveraged here to help make these decisions along with statistical analysis tools and data mining tools.
The Business Intelligence tool that we are going to learn is SSIS which uses SQL as the Backend, Sonow let us learn the SQL Basics
Sunday, 29 July 2018
What is a Dimension Table and Types of Dimension table
What
is a Dimension Table:
If a Table contains “primary keys” and it gives the detailed information
about business then such a table is called dimension table.
A Dimension table is a table which holds a list of attributes or
qualities of the dimension most often used in queries and reports.
E.g. “Store” dimension can have attributes
Street,
Block Number,
City,
Region,
Country where it is located in addition to its name.
Dimension tables are ENTRY POINTS into the fact table.
1. The number of rows selected and processed from the fact table depends
on the conditions (“WHERE” clauses) the user applies on the dimensional
attributes selected.
2. Dimension tables are typically DE-NORMALIZED in order to reduce the
number of joins in resulting queries. Dimension table attributes are generally
STATIC, DESCRIPTIVE fields describing aspects of the dimension Dimension tables
typically designed to hold IN-FREQUENT CHANGES to attribute values over time
using SCD concepts Dimension tables are TYPICALLY used in GROUP BY SQL queries
Every column in the dimension table is TYPICALLY either the primary key or a
dimensional attribute Every non-key column in the dimension table is typically
used in the GROUP BY clause of a SQL Query.
Types of Dimension table:
1.Conformed Dimension:
If a dimension table is shared by multiple fact tables then that dimension is known as conformed dimension table.

If a dimension table is shared by multiple fact tables then that dimension is known as conformed dimension table.

2.Junk dimension:
Junk dimensions are dimensions that contain miscellaneous data like flags, gender, text values etc and which are not useful to generate reports.
Junk dimensions are dimensions that contain miscellaneous data like flags, gender, text values etc and which are not useful to generate reports.

3.Slowly changing
dimension:
If the data values are changed slowly in a column or in a row over the period of time then that dimension table is called as slowly changing dimension.
If the data values are changed slowly in a column or in a row over the period of time then that dimension table is called as slowly changing dimension.
Ex: Interest rate, Address of customer etc
There are three types of
SCD’s:
Type – 1 SCD: A
type-1 dimension keeps the most recent data in the target.
Type – II SCD: keeps
full history in the target. For every update it keeps a new record in the
target.
Type – III SCD: keeps
the current and previous information in the target (partial history).
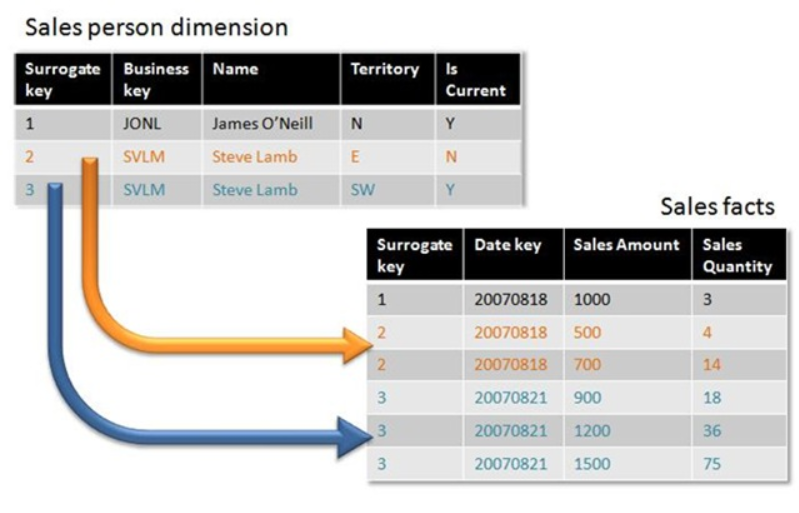
Note: To implement
SCD2 we use Surrogate key.
Example1:


Example1:

Example2:

Surrogate key:
1. Surrogate Key is
an artificial identifier for an entity. In surrogate key values are generated
by the system sequentially (Like Identity property in SQL Server and Sequence
in Oracle). They do not describe anything.
2. Joins between fact
and dimension tables should be based on surrogate keys
3. Surrogate keys
should not be composed of natural keys glued together
4. Users should not
obtain any information by looking at these keys
5. These keys should
be simple integers
6. Using surrogate
key will be faster
7. Can handle Slowly
Changing dimensions

4.Degenerated dimension:
A degenerate dimension is data that is dimensional in nature but stored in a fact table. For example, if you have a dimension that only has Order Number and Order Line Number, you would have a 1:1 relationship with the Fact table. Therefore, this would be a degenerate dimension and Order Number and Order Line Number would be stored in the Fact table. Fast Changing Dimension: A fast changing dimension is a dimension whose attribute or attributes for a record (row) change rapidly over time. Example: Age of associates, Income, Daily balance etc.


A degenerate dimension is data that is dimensional in nature but stored in a fact table. For example, if you have a dimension that only has Order Number and Order Line Number, you would have a 1:1 relationship with the Fact table. Therefore, this would be a degenerate dimension and Order Number and Order Line Number would be stored in the Fact table. Fast Changing Dimension: A fast changing dimension is a dimension whose attribute or attributes for a record (row) change rapidly over time. Example: Age of associates, Income, Daily balance etc.

5.Roll playing
dimension:
One
dimension plays multiple roles to retrieve data from fact tables.
6.Dirty dimension:
In this dimension table records are maintained more than once by the difference of non-key attributes.
Surrogate key in Datawarehousing
Surrogate key:
1. Surrogate Key is an artificial identifier
for an entity. In surrogate key values are generated by the system sequentially
(Like Identity property in SQL Server and Sequence in Oracle). They do not
describe anything.
2. Joins between fact and dimension tables should be based
on surrogate keys
3. Surrogate keys should not be composed of natural keys
glued together
4. Users should not obtain any information by looking at these
keys
5. These keys should be simple integers
6. Using surrogate key will be
faster
7. Can handle Slowly Changing dimensions well
Types of Facts
Types of Facts:
There
are three types of facts:
1. Additive - Measures that can be added across all
dimensions.
2. Semi Additive - Measures that can be added across few dimensions
and not with others.
3. Non Additive - Measures that cannot be added across all
dimensions.
Sunday, 22 July 2018
Data warehouse ETL Products
Data
warehouse
ETL Products:
1. CODE BASED ETL TOOLS
2. GUI BASED ETL TOOLS
Code Based ETL Tools: In these tools, the data acquisition process can be developed with the help of programming languages.
1. SAS ACCESS
2. SAS BASE
3. TERADATA ETL TOOLS
a. BTEQ (Batch TEradata Query)
b. TPUMP (Trickle PUMP)
c. FAST LOAD
4. MULTI LOAD Here the application Development, Testing, and Maintenance is costlier process compared to GUI based tools.
GUI based ETL Tools:
1. Informatica
2. DT/Studio
3. Data Stage
4. Business Objects Data Integrator (BODI)
5. AbInitio
6. Data Junction
7. Oracle Warehouse Builder
8. Microsoft SQL Server Integration Services
9. IBM DB2 Ware house Center
1. CODE BASED ETL TOOLS
2. GUI BASED ETL TOOLS
Code Based ETL Tools: In these tools, the data acquisition process can be developed with the help of programming languages.
1. SAS ACCESS
2. SAS BASE
3. TERADATA ETL TOOLS
a. BTEQ (Batch TEradata Query)
b. TPUMP (Trickle PUMP)
c. FAST LOAD
4. MULTI LOAD Here the application Development, Testing, and Maintenance is costlier process compared to GUI based tools.
GUI based ETL Tools:
1. Informatica
2. DT/Studio
3. Data Stage
4. Business Objects Data Integrator (BODI)
5. AbInitio
6. Data Junction
7. Oracle Warehouse Builder
8. Microsoft SQL Server Integration Services
9. IBM DB2 Ware house Center
Star Schema and Snowflake Schema
Star Schema and Snowflake Schema:
Schema : A schema is a collection of objects including tables, views, indexes and synonyms
Star Schema: A Star schema is a logical database design which contains a centrally located fact table surrounded by dimension tables. The data base design looks like a star. Hence it is called as “Star schema”.

The star schema is also called "star-join schema".
Advantages of Star schema:
1. Star schema is very easy to understand , even for non technical business managers.
2. Provides better performance and smaller query times.
3. Star schema is easily understandable and will handle future changes easily.
Snowflake Schema: The snowflake schema is similar to the star schema. However, in the snowflake schema, dimensions are normalized into multiple related tables, whereas the star schema's dimensions are denormalized with each dimension represented by a single table. A large dimension table is split into multiple dimension tables.
Schema : A schema is a collection of objects including tables, views, indexes and synonyms
Star Schema: A Star schema is a logical database design which contains a centrally located fact table surrounded by dimension tables. The data base design looks like a star. Hence it is called as “Star schema”.

The star schema is also called "star-join schema".
Advantages of Star schema:
1. Star schema is very easy to understand , even for non technical business managers.
2. Provides better performance and smaller query times.
3. Star schema is easily understandable and will handle future changes easily.
Snowflake Schema: The snowflake schema is similar to the star schema. However, in the snowflake schema, dimensions are normalized into multiple related tables, whereas the star schema's dimensions are denormalized with each dimension represented by a single table. A large dimension table is split into multiple dimension tables.
E-R Modeling and Dimensional Modeling
E-R Modeling and Dimensional Modeling:
E-R Modeling :In this E-R Modeling technique for the purpose of the retriving data, we need to apply "More" number of joins .
DWH projects we need to deal with Current data and History data for that reason all tables are having huge amount of data.On huge amount of data tables if we are apply more number of Joins Query Performance completely "degrade".

Dimensional Modeling:In this Dimensional Modeling technique for the purpose of the retriving data, we need to apply "Less" number of joins .
DWH projects we need to deal with Current data and History data for that reason all tables are having huge amount of data.On huge amount of data tables if we are apply Less number of Joins Query Performance "Increased".

E-R Modeling :In this E-R Modeling technique for the purpose of the retriving data, we need to apply "More" number of joins .
DWH projects we need to deal with Current data and History data for that reason all tables are having huge amount of data.On huge amount of data tables if we are apply more number of Joins Query Performance completely "degrade".

Dimensional Modeling:In this Dimensional Modeling technique for the purpose of the retriving data, we need to apply "Less" number of joins .
DWH projects we need to deal with Current data and History data for that reason all tables are having huge amount of data.On huge amount of data tables if we are apply Less number of Joins Query Performance "Increased".

Types of Data warehouse
Types of Data warehouse:
Note: "Data Modeler" decide which model is best
There are three types of data warehouses:
1.Centralized Data Warehouse
2.Federated Data Warehouse
Centralized data warehouse: A centralized DWH is one in which data is stored in a single, large primary database. This database can be queried directly or used to feed data marts.

Federated data warehouse: For the purpose of simplifying the data we can go for Federated data warehouse
A federated DWH is an active union and cooperation across separate DWHs.
1. Different DWHs communicate
2. Requires active cooperation across multiple DWHs
3. No passive co-existence of separate systems
To build data warehouse there are two approaches:
Data Mart:Data Mart is nothing but subset of Data Warehouse and only single subject area.
Data mart is a decentralized subset of data found either in a data warehouse or as a standalone subset designed to support the unique business requirements of a specific decision-support system. A data mart is a subject-oriented database which supports the business needs of middle management like departments. A data mart is also called High Performance Query Structures (HPQS).
Dependent data marts: In the top-down approach data mart development depends on enterprise data warehouse. Such data marts are called as dependent data marts. Dependent data marts are marts that are fed directly by the DWH, sometimes supplemented with other feeds, such as external data Independent data marts: In the bottom -up approach data mart development is independent on enterprise data warehouse. Such data marts are called as independent data marts. Independent data marts are marts that are fed directly by external sources and do not use the DWH. Embedded data marts are marts that are stored within the central DWH. They can be stored relationally as files or cubes.
Data Mart Main Features:
1. Low cost
2. Contain less information than the warehouse
3. Easily understood and navigated than an enterprise data warehouse.
4. Within the range of divisional or departmental budgets
Data Mart Advantages:
1. Typically single subject area and fewer dimensions
2. Focused user needs
3. Limited scope
4. Optimum model for DWH construction
5. Very quick time to market (30-120 days)
1. Top-Down Approach
2. Bottom-Up Approach
Note: "Data Modeler" decide which model is best
There are three types of data warehouses:
1.Centralized Data Warehouse
2.Federated Data Warehouse
Centralized data warehouse: A centralized DWH is one in which data is stored in a single, large primary database. This database can be queried directly or used to feed data marts.

Federated data warehouse: For the purpose of simplifying the data we can go for Federated data warehouse
A federated DWH is an active union and cooperation across separate DWHs.
1. Different DWHs communicate
2. Requires active cooperation across multiple DWHs
3. No passive co-existence of separate systems
To build data warehouse there are two approaches:
Data Mart:Data Mart is nothing but subset of Data Warehouse and only single subject area.
Data mart is a decentralized subset of data found either in a data warehouse or as a standalone subset designed to support the unique business requirements of a specific decision-support system. A data mart is a subject-oriented database which supports the business needs of middle management like departments. A data mart is also called High Performance Query Structures (HPQS).
Dependent data marts: In the top-down approach data mart development depends on enterprise data warehouse. Such data marts are called as dependent data marts. Dependent data marts are marts that are fed directly by the DWH, sometimes supplemented with other feeds, such as external data Independent data marts: In the bottom -up approach data mart development is independent on enterprise data warehouse. Such data marts are called as independent data marts. Independent data marts are marts that are fed directly by external sources and do not use the DWH. Embedded data marts are marts that are stored within the central DWH. They can be stored relationally as files or cubes.
Data Mart Main Features:
1. Low cost
2. Contain less information than the warehouse
3. Easily understood and navigated than an enterprise data warehouse.
4. Within the range of divisional or departmental budgets
Data Mart Advantages:
1. Typically single subject area and fewer dimensions
2. Focused user needs
3. Limited scope
4. Optimum model for DWH construction
5. Very quick time to market (30-120 days)
1. Top-Down Approach
2. Bottom-Up Approach
Top-Down
Approach: This approach is developed by W.H.Inmon. According to him
first we need to develop enterprise data warehouse. Then from that enterprise
data warehouse develop subject orient databases.
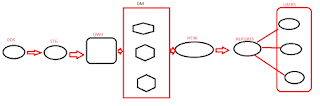

Bottom-Up Approach:
This approach is developed by Ralph Kimball. According to him first we need to develop
the data marts to support the business needs of middle-level management. Then
integrate all the data marts into an enterprise data warehouse.


Top Down
|
Bottom Up
|
More planning and design initially
|
Can plan initially without waiting
for global infrastructure
|
Involve people from different
workgroups, departments
|
Built incrementally
|
Data marts may be built later from
Global DW
|
Can be built before or in parallel
with Global DW
|
Overall data model to be decided
upfront
|
Less complexity in design
|
High cost, lengthy process, time
consuming.
|
Low cost of Hardware and other
resources.
|
Involved people from different work
groups, departments.
|
It is built in the incremental
manner.
|
Saturday, 21 July 2018
Differences between ODS and Data Warehouse (or) OLTO and OLAP:
Differences between ODS and Data Warehouse (or) OLTP and OLAP:
ODS
|
DWH
|
Non Redendent data
|
Redendent data Available
|
Less amount of data here
|
Huge amount of data here
|
End user Employee
|
End user CEO , high level managenent
people
|
Using OLTP technology
|
Using OLAP technology
|
Running the business
|
Analysing the business
|
Not maintain history
|
Mintain History also
|
Having UnOrganiesd data
|
Having Organised data
|
Application oriented data
|
Subject oriented data
|
Current data
|
Historical data
|
Detailed data
|
Summary data
|
Volatile data
|
Non-volatile data
|
Less history (3-6 months)
|
More history (5-10 years)
|
Normalization data
|
De-normalization data
|
Designed for running the business
|
Designed for analyzing the business
|
Supports E-R modeling
|
Supports Dimensional modeling
|
Clerical users can access this data
|
Knowledge users can access this data
|
DB Size – 100MB-GB
|
DB Size – 100GB-TB
|
Few Indexes
|
Many Indexes
|
Many Joins
|
Some Joins
|
It is designed to support business
transactional processing.
|
It is designed to support decision
making process.
|
Data Warehouse
What is Data Warehouse:
The First Data Warehousing System is implemented in 1987 by Inmon.
Data warehouse is a relational database that is designed for querying and analyzing the business but not for transaction processing.It usually contains historical data derived from transactional data (different source systems).
Data Warehouse is nothing but collection of data from different types of source systems and we are converting that data into organised format for the purpose of doing analysis to take the decision.
Data Warehouse is not a technology, the combination of multiple technologies(Reporting tool,ETL Tools,DB)
Depending on Requirement to design the DWH
Data Warehouse is not a technology, the combination of multiple technologies(Reporting tool,ETL Tools,DB)
Depending on Requirement to design the DWH
Advantages of Data Warehouse
Advantages of Data Warehouse :
1.To Store Large Volumes of
Historical Detail Data from Mission Critical Applications.
2.Better business
intelligence for end-users.
3.Data Security - To prevent unauthorized access to
sensitive data.
4.Replacement of older, less-responsive decision support
systems.
5.Reduction in time to locate, access, and analyze information.
6.For the purpose of doing analysis and to take the decision.
7.High query performance.
8.Queries not visible outside warehouse.
9.Can operate when sources unavailable.
10.Can query data not stored in a DBMS.
11.Extra information at warehouse
12.Modify, summarize (store aggregates).
13.Add historical information 6. Improves the quality and accessibility of data.
14.Reduce the requirements of users to access operational data.
15.Allows new reports and studies to be introduced without disrupting operational systems.
16.Increases the amount of information available to users.
6.For the purpose of doing analysis and to take the decision.
7.High query performance.
8.Queries not visible outside warehouse.
9.Can operate when sources unavailable.
10.Can query data not stored in a DBMS.
11.Extra information at warehouse
12.Modify, summarize (store aggregates).
13.Add historical information 6. Improves the quality and accessibility of data.
14.Reduce the requirements of users to access operational data.
15.Allows new reports and studies to be introduced without disrupting operational systems.
16.Increases the amount of information available to users.
Data Warehouse Characteristics
Characteristic
features of Data Warehouse:


1.Subject
Oriented
2.Integrated
3.Nonvolatile
4.Time variant
Subject Oriented:The data
warehouses are designed as a Subject-oriented that are used to analyze the
business by top level management, or middle level management, or for a
individual department in an enterprise.

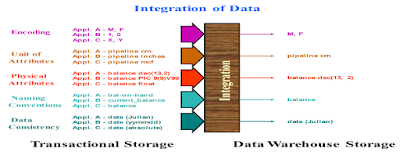

Integrated:Data
warehouse is an integrated database which contains the business information collected
from various operational data sources.

Time Variant:Data
warehouse is a time variant database which allows you to analyze and compare
the business with respect to various time periods (Year, Quarter, Month, Week,
Day) because which maintains historical data.

Non-Volatile:Data
warehouse is a non-volatile database. That means once the data entered into
data warehouse cannot change. It doesn’t reflect to the changes taken place in
operational database. Hence the data is static.

Subscribe to:
Comments (Atom)